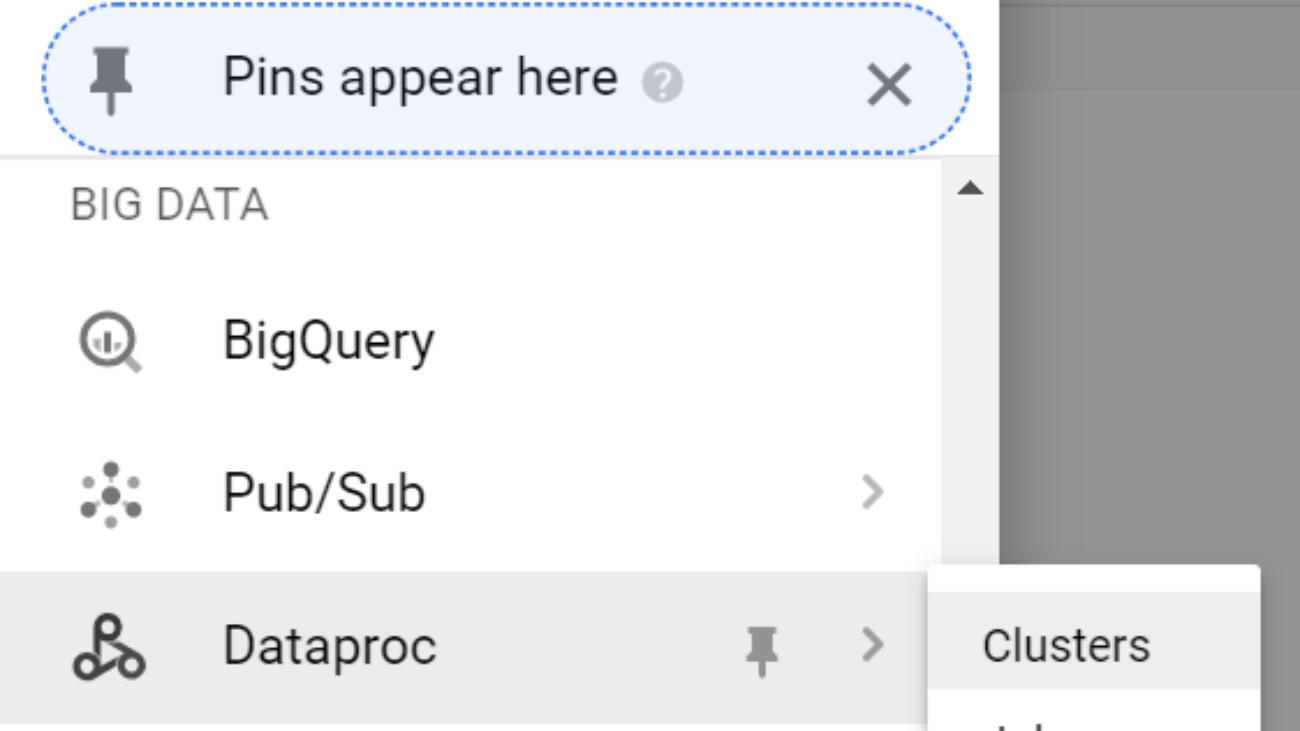
1. Tạo Cluster Dataproc
1.1 Click vào menu di chuyển tới Dataproc và click vào Clusters

1.2 Click vào button Create Cluster

1.3 Cấu hình Cluster
Đặt tên cho ClusterChọn Machine type cụ thể cho Master node và kích thước ổ đĩa chính.
Chọn Machine type cho các Worker node và chỉ định số lượng node cần theo yêu cầu của bạn.
Bạn có thể đi vào chi tiết hơn bằng cách click vào Advanced options để tùy chỉnh Preemptible workers, bucket, network, version, initialization, & access options
Sau đó click vào nút Create để tạo Cluster

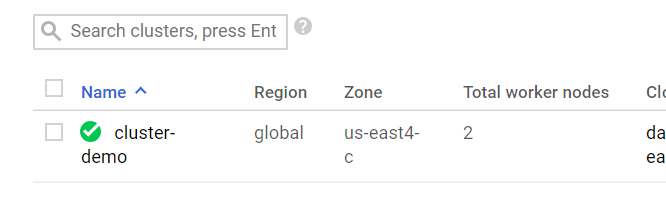
Chờ trong khoảng 90 giây để khởi tạo Cluster của bạn. Khi tạo xong sẽ có dấu check màu xanh lá.

2. Cài đặt network
Trong khi chờ đợi Cluster tạo thì chúng ta vào cài đặt network
2.1 Click vào menu di chuyển tới VPC network và click vào Firewall rules

2.2 Click vào Create Firewall Rule để tạo một Firewall rule giúp ta có thể truy cập vào Cluster vừa tạo.

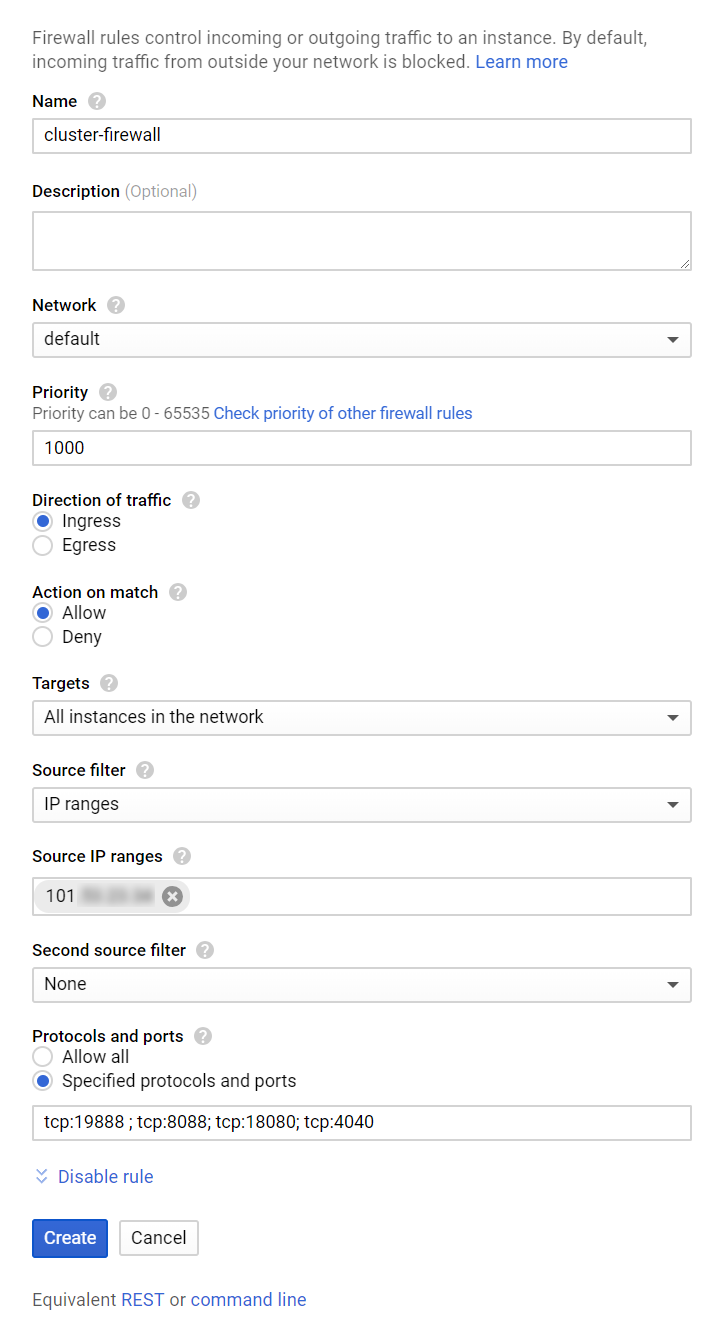
2.3 Cấu hình rule
Đặt tên cho Rule
Chọn network sẽ áp dụng rule, ở đây mình chọn default vì khi tạo cluster mình tạo ở network default.
Target chọn là All instances in the network
Source IP ranges điền ip hiện tại của bạn vào. Để xem ip bạn có thể vào trang whatismyip.com để xem ip của mình.
Protocols and ports chọn Specified protocols and ports và điền các port sau vào tcp:19888 ; tcp:8088; tcp:18080; tcp:4040
Nhấn nút Create để tạo Firewall rule
3. Kiểm tra Cluster
3.1 Click vào menu di chuyển tới Compute Engine và click vào VM instances
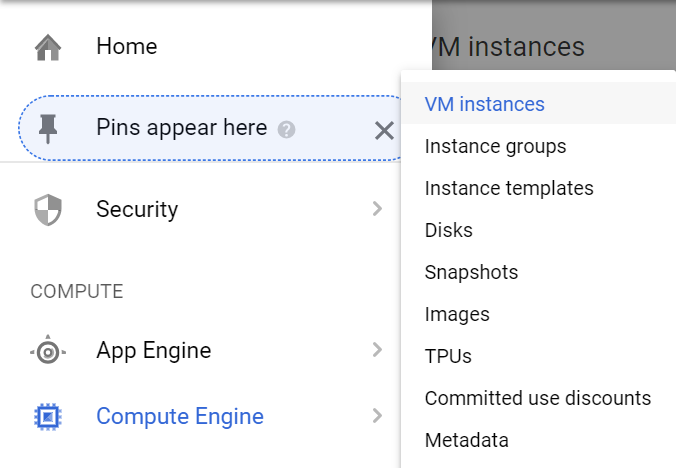
3.2 Xem External IP của Master Node của bạn. Nó là máy có tên cluster của bạn kèm theo -m

3.3 Mở trình duyệt và gõ vào địa chỉ ip vừa lấy cùng với port là 8088 bạn sẽ thấy màn hình hadoop và port 14040 để vào màn hình history của Spark
Hadoop

Spark

4.Chạy thử Spark Cluster
Vậy là bạn đã tạo xong Cluster và truy cập được vào nó tiếp theo mình sẽ tạo 1 job đơn giản cho Spark
4.1 Quay lại Menu Dataproc và click vào Jobs

4.2 Click vào nút Submit Job để tạo job mới

4.3 Cấu hình cho job
Đặt tên cho Job của bạn.
Region chọn vùng lúc bạn tạo Cluster
Cluster chọn Cluster bạn đã tạo
Job Type chọn Spark
Main class or jar điền vào là org.apache.spark.examples.SparkPi
Arguments điền 1000
Jar files điền vào file:///usr/lib/spark/examples/jars/spark-examples.jar
Và nhấn nút Submit

4.4 Sau khi submit bạn có thể thấy được job của mình vừa tạo đang thực thi.

Để có được thông trực tiếp đang chạy bạn có thể mở browser gõ vào địa chỉ id của Cluster với port là 4040 bạn sẽ vào được màn hình Jobs của Spark hoặc port 18080 để vào màn hình History của Spark


Bạn cũng có thể click vào tên của job để xem thông tin chi tiết của job sau khi chạy xong.

Vậy là bạn đã có thể tạo và chạy thử một Spark Cluster.