
Phần 2 -2 : Xây dựng matrix factorization-based collaborative filtering Recommendation System trên GCP
Chào mọi người ngày mới, hy vọng là mọi người vẫn còn nhớ 4 bước xây dựng hệ thống gợi ý matrix factorization Recommendation System trên GCP, lần trước mình đã giới thiệu bước 1 cho mọi người rồi, lần này thì tiếp tục ở bước 2 nhé. Dành cho những bạn chưa nắm được 4 bước này là gì thì mình ghi lại ở đây nhé
- Bước 1: Xây dựng model: Bước này sẽ giới thiệu cho các bạn cách dùng thuật toán WALS trong TF để tạo dự đoán về rating phim.
- Bước 2: Train và Tune model trên AI platform: Bước này mình sẽ giới thiệu cho các bạn cách training model, tuning hyperparameters để optimize model.
- Bước 3: Tiếp đến là ứng dụng model đã tạo cho data từ Google Analytics: Ở bước này mình và các bạn sẽ tìm hiểu cách để ứng dụng hệ thống recommendation cho data được lấy từ Google Analytic 360 để thực hiện recommendation cho các website sử dụng Analytics.
- Bước 4: Deploy hệ thống recommendation: cùng nhau thực hiện việc deploy hệ thống này lên GCP để hệ thống có thể chạy real-time recommendation trên các website.
Giờ thì bắt tay vào việc Train và Tune model thôi nào. Lần này mình sẽ cùng các bạn tìm hiểu 2 chủ đề nhỏ chính nè. Đầu tiên là học cách training job trên AI Platform GCP trên dataset MovieLens lần trước nè. Sau đó sẽ là công việc Tune AI Platform hyperparameters và optimize TensorFlow WALS recommendation model cho MovieLens dataset.
Nhớ start lại bé VM nếu lần trước bạn có stop nhé.
Training jobs trên AI Platform
Để training model rên AI Platform bạn cần chỉ định cụ thể một job directory cùng với đó là Cloud Storage bucket folder. Để chạy training job thì cần 3 bước sau.
- Tại mới Cloud Storage bucket trên project của bạn hoặc dùng cái đã có sẵn cũng được nhé.
Để tao mới một bucket thì bạn có thể làm như sau: trong Cloud Console, chọn Cloud Storage > Browser, và sau đó nhấn click Create Bucket. Lưu ý là nên đặt tên của bucket mang tính gợi nhớ và nằm cùng region với region của Compute Engine instance.


- Active shell lên nếu bạn chưa làm và cài đặt environment variable BUCKET của Cloud Storage bucket URL bucket mà bạn dùng nhé
BUCKET=gs://[YOUR_BUCKET_NAME]
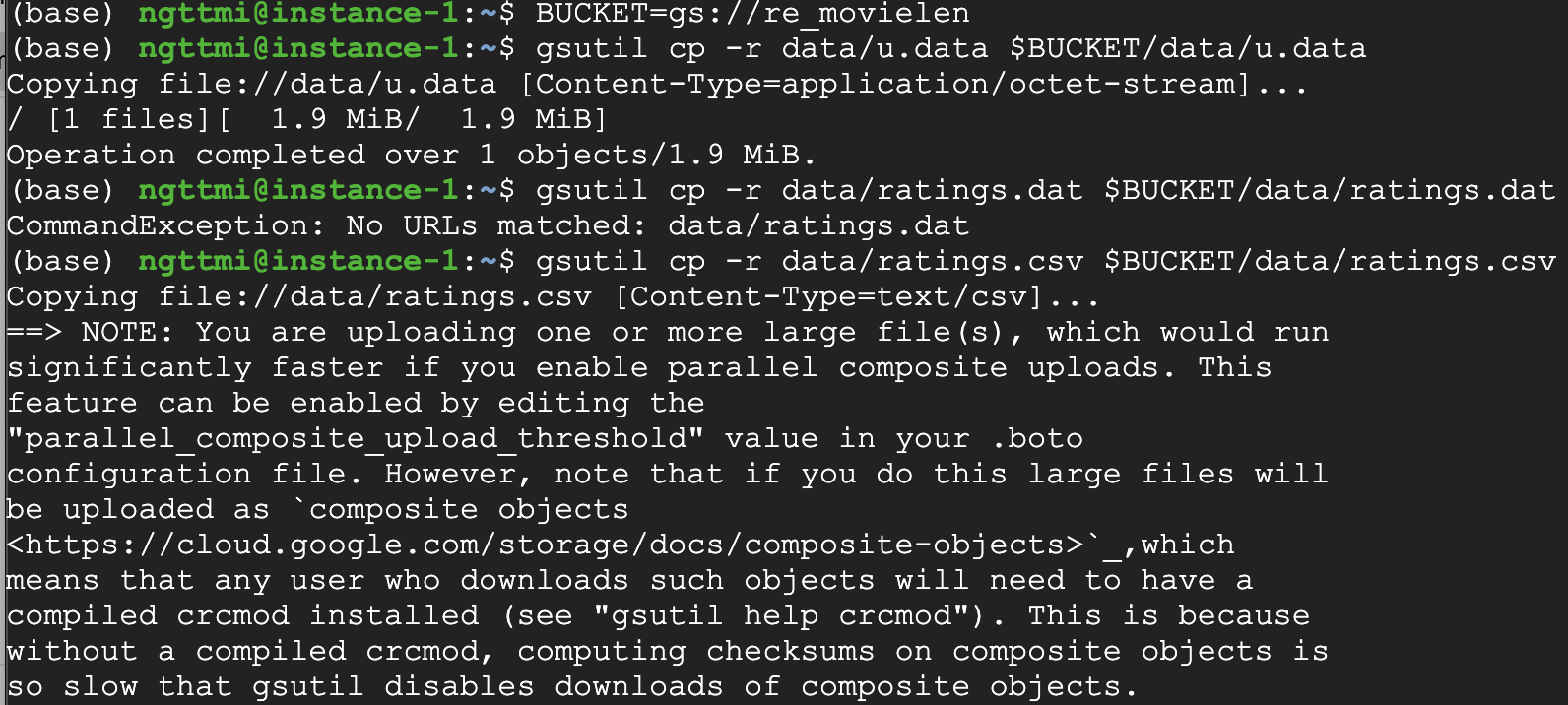
- Copy MovieLens datasets vào bucket của bạn bằng gsutil tool:
gsutil cp -r data/u.data $BUCKET/data/u.data
gsutil cp -r data/ratings.dat $BUCKET/data/ratings.dat
gsutil cp -r data/ratings.csv $BUCKET/data/ratings.csv
- Running training script trong the wals_ml_engine.
Tùy thuộc vào cấu trúc thư mục của bạn thì hãy cd wals_ml_engine nhé
Với MovieLens 100k dataset mà mình đã chọn lúc đầu, thực thi câu lệnh sau
./mltrain.sh train ${BUCKET} data/u.data
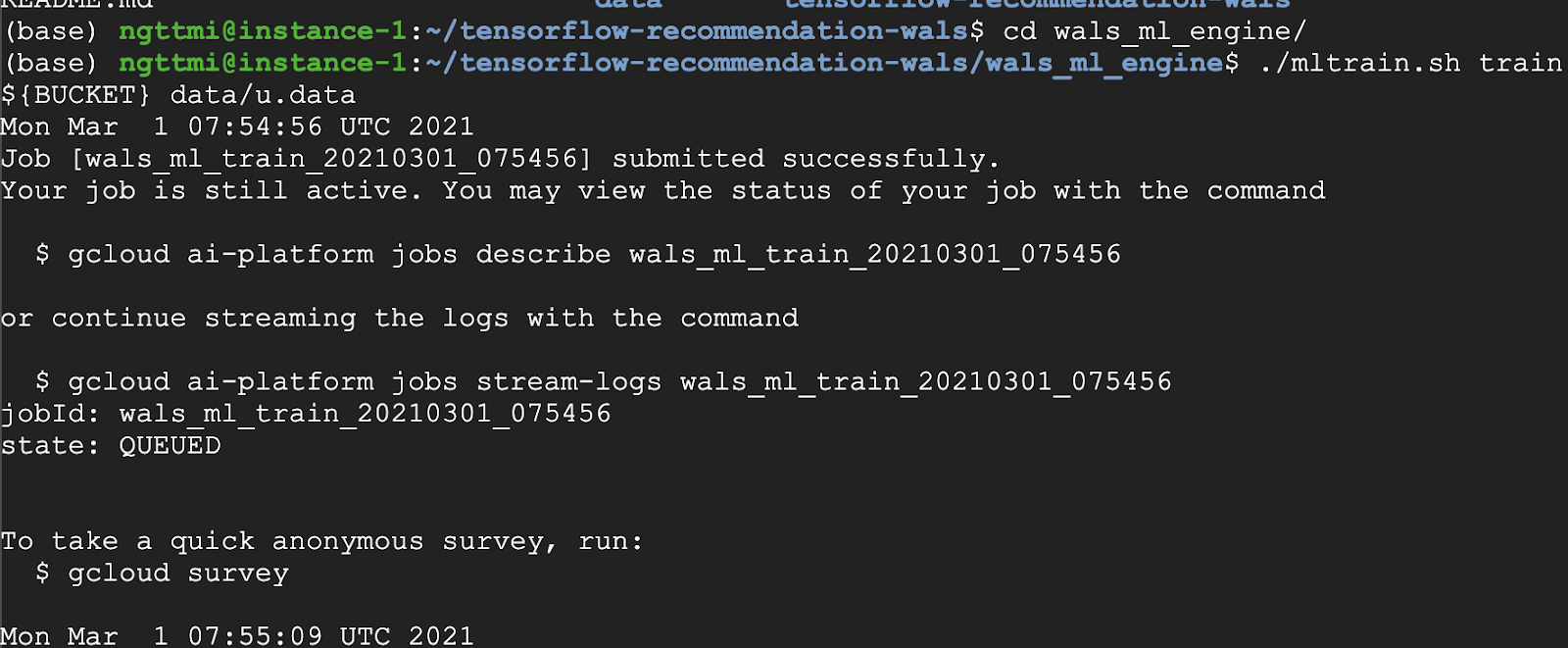
Bạn có thể kiểm tra và xem lại thông tin trên Logs của AI Platform trên GCP nhé

Lưu model
Sau khi factorization, factor matrix được lưu thành 5 file riêng biệt dưới dạng numpy format sau đó bạn có thể dùng file này để thực thi hệ thống recommendations của bạn rồi. Trong phần 2-3 mình sẽ giải thích cho các bạn về 5 files này và hướng dẫn cách generate ra recommendations từ 5 files này nhé. Khi bạn training model dưới máy local các files này được lưu trong cùng folder chứa package code của bạn. Còn hiện tại chúng ta đang chạy model trên AI Platform của GCP nên các file này sẽ được lưu trữ trong Cloud Storage bucket mà lúc nãy các bạn vừa trỏ tới.
MovieLens dataset results
Kết quả của matrix factorization approximations dựa trên predicted ratings của test set. Test set được extract từ ratings matrix trong quá trình preprocessing. Để tính toán sự khác biệt giữa predicted rating và actual user-supplied test set ratings bạn có thể dùng Loss function để tính toán nhé.
Hiệu suất của matrix factorization phụ thuộc khá nhiều vào các thuộc tính hyperparameters. Trong model vừa rồi, chúng ta đang dùng các chỉ số mặc định cho hyperparameters, mình để bên dưới nha, để cải thiện được model mình có thể update lại các chỉ số cho hyperparameters.
| Hyperparameter name and description | Default Value | Scale |
| latent_factorsNumber of latent factors K | 5 | UNIT_REVERSE_LOG_SCALE |
| regularizationL2 Regularization constant | 0.07 | UNIT_REVERSE_LOG_SCALE |
| unobs_weightWeight on unobserved ratings matrix entries | 0.01 | UNIT_REVERSE_LOG_SCALE |
| feature_wt_factorWeight on observed entries | 130 | UNIT_LINEAR_SCALE |
| feature_wt_expFeature weight exponent | 1 | UNIT_LOG_SCALE |
| num_itersNumber of alternating least squares iterations | 20 | UNIT_LINEAR_SCALE |
Tuning hyperparameters
Công việc tìm ra thống số thích hợp bộ hyperparameters là một việc rất quan trọng. Tuy nhiên hiện tại có rất ít hướng dẫn để hướng dẫn cách thức tìm ra được giá trị phù hợp. Kết quả có của bộ hyperparameters thường được tìm thấy thông qua quá trình thử nghiệm nhiều lần, kiểm chứng lại dữ liệu và thông thường quá trình này tốn rất nhiều thời gian và công sức.
Câu chuyện này sẽ được thay đổi nếu bạn dùng AI Platform của GCP. AI Platform trên GCP có chứ luôn hyperparameter tuning feature, thao tác này sẽ được thực hiện tự động và trả về cho bạn bộ hyperparameters nhất. Để dùng được tuning feature, bạn có thể cung cấp danh sách của các hyperparameter mà bạn muốn tune và các giá trị expected range của các tham số này. AI Platform sẽ tiến hành thực thi tìm kiếm trong space của hyperparameters, thực thi nhiều lần và trả về kết quả tốt nhất.Bạn có thể tìm hiểu thêm thông tin của AI Platform documentation ở đây nhé.
Run the hyperparameter tuning job
Với dataset 100k đã chọn thì bạn thực thi câu lệnh dưới đây để tune nhé.
./mltrain.sh tune $BUCKET data/u.data
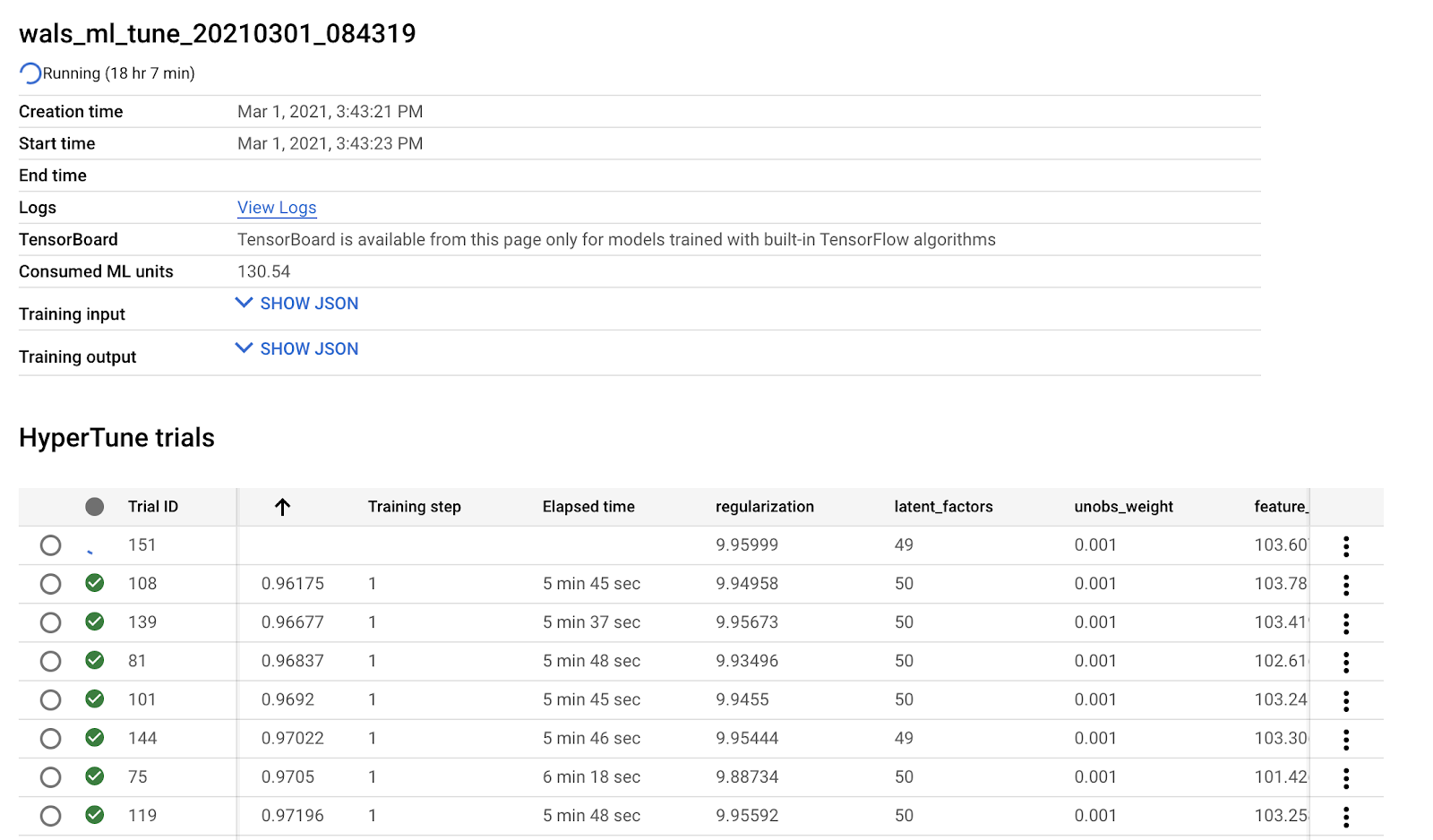
Dưới đây là bảng giá trị các Hyperparameter sau khi được tuning
| Hyperparameter name | Description | Value from tuning |
| latent_factors | Latent factors K | 34 |
| regularization | L2 Regularization constant | 9.83 |
| unobs_weight | Unobserved weight | 0.001 |
| feature_wt_factor | Observed weight | 189.8 |
| feature_wt_exp | Feature weight exponent | N/A |
| num_iters | Number of iterations | N/A |
Dưới đây là kết quả của model khi không chạy tune

Thời gian chạy tune của model khá lâu nên bạn cần kiên nhẫn nhé. Nhưng đem lại kết quả tốt hơn rất nhiều nè.
Trong bài viết lần sau bạn hãy cùng mình tìm hiểu rõ hơn về các tham số nhé ^^