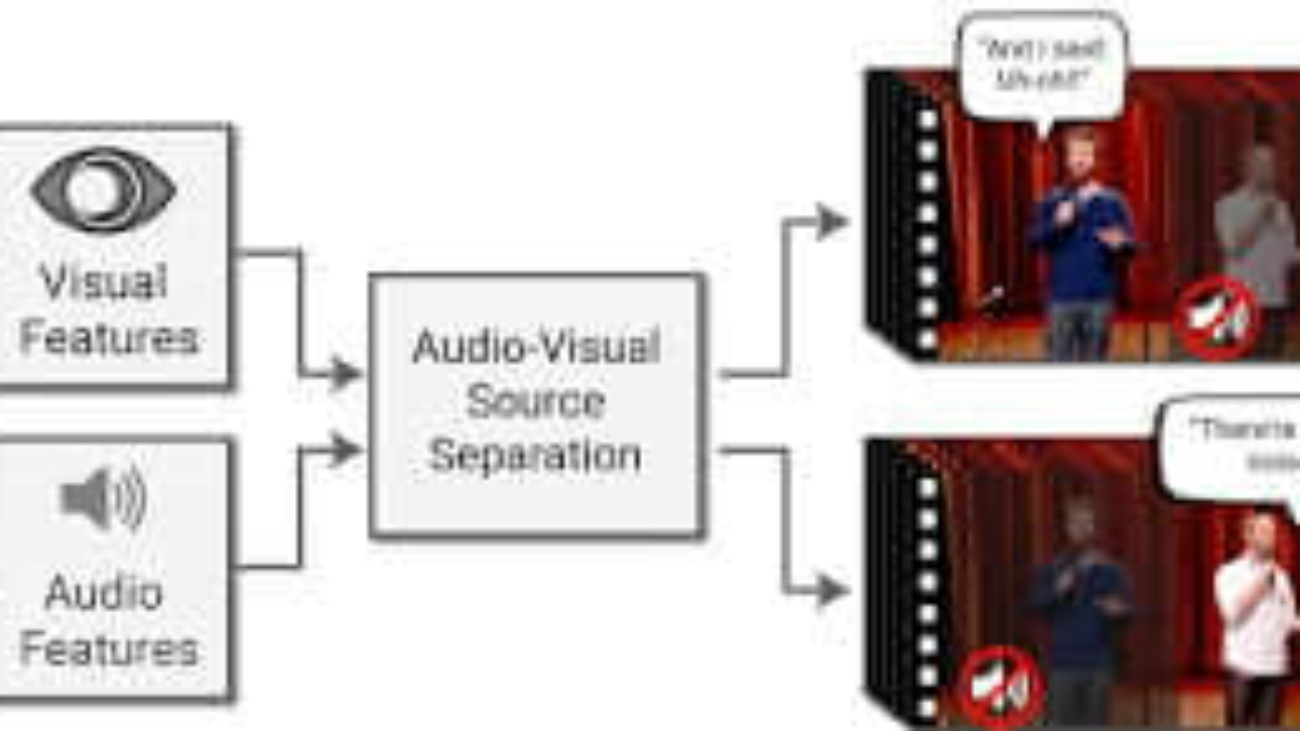
Google vừa công bố mô hình trích xuất giọng nói của một người từ nhiều tạp âm với tên gọi “Looking to Listen at the Cocktail Party”
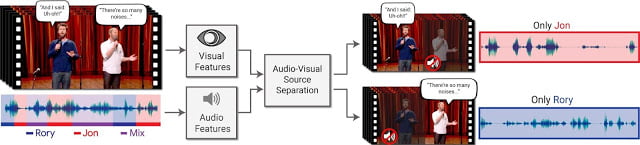
Đoạn clip bên dưới sẽ giúp các bạn hiểu rõ hơn.
Trong clip, hai người đồng thời nói về hai nội dung khác nhau. Mô hình trên sẽ giúp bạn tự do chọn một parameter rồi điều khiển sao cho chỉ nghe theo một người duy nhất.
Với mô hình sử dụng Deep learning để phân tán đồng nhất các tín hiệu âm thanh đang phát ra từ nhiều nguồn, các nhà phát triển có thể tạo dựng các đoạn video loại bỏ tạp âm và chỉ tập trung vào lời nói của một người duy nhất.
Đoạn video được đưa vào xử lý có thể chạy trên các audio track thông thường, sau đó người dùng có thể click chọn vào khuôn mặt của người nói để hệ thống tự động xử lý lọc tạp âm.
Mô hình “Looking to Listen at the Cocktail Party” dựa trên việc phân tích đồng thời quan hệ giữa tín hiệu âm thanh và khẩu hình từ cả hai người trong video, để cho ra được kết quả chính xác nhất.
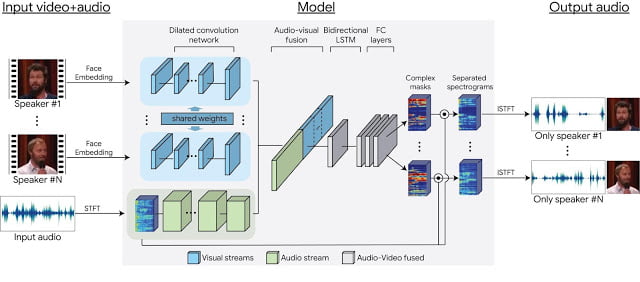
Tính năng này sẽ có ích trong việc trích xuất âm thanh từ một nguồn duy nhất trong các buổi thảo luận, hay trong một ca khúc của các nhóm nhạc.