HDFS ( Hadoop Distributed File System) nó là 1 hệ thống lưu trữ chính được dùng bởi Hadoop. Nó cung cấp truy cập hiệu suất cao đến dữ liệu trên các cụm Hadoop.
Cloud Storage: Kho lưu trữ dữ liệu đối tượng có kiến trúc rất khác so với HDFS. Nhiều mô hình được phát triển cụ thể xung quanh HDFS.
Cho dù bạn sử dụng lưu trữ đối tượng hoặc sử dụng HDFS thì việc di chuyển dữ liệu từ trung tâm dữ liệu (on-prem) sang đám mây để lưu trữ có thể giúp bạn giảm đáng kể chi phí duy trì hoạt động.
Ưu điểm và Khuyết điểm của Cloud Storage và HDFS.
Việc di chuyển từ HDFS sang Cloud Storage có một số đánh đổi. Sau đây là ưu và khuyết điểm
I. Khuyết điểm
1. Cloud Storage có thể làm tăng độ lệch I/O
Trong nhiều tình huống, Cloud Storage có tốc độ I/O cao hơn HDFS. Điều này có thể có vấn đề nếu bạn yêu cầu I/O nhất quán, chẳng hạn như ứng dụng hỗ trợ HBase hoặc cơ sở dữ liệu NoSQL khác. Mặc dù sai lệch I/O có thể được giảm thiểu bằng bộ nhớ đệm hoặc đọc bản sao, bạn cũng có thể xem xét phương pháp thay thể là Cloud Bigtable hoặc Cloud Datastore.
2. Cloud Storage không hỗ trợ nối hoặc cắt ngắn nội dung trong file.
Trên Cloud Storage, đối tượng là bất biến có nghĩa là các đối tượng được tải lên không được thay đổi trong suốt quá trình lưu trữ của nó. Trong thực tế, điều này có nghĩa là bạn có thể thực hiện các thay đổi nội dung của đối tượng như nối-cắt nội dung của đối tượng. Bạn chỉ có thể ghi đè đối tượng.
3. Cloud Storage không tuân thủ POISIX
Công bằng mà nói thì HDFS cũng không hoàn toàn tuân thủ POISIX. Tuy nhiên, qua nhiều năm, HDFS đã tích hợp được nhiều tính năng giống POISIX và các nhà phát triển đã xây dựng nên các ứng dụng Hadoop và Spark để tận dụng các tính năng có thể không hoạt động tốt trên Cloud Storage. Ví dụ như đổi tên thự mục. Trên Cloud Storage thư mục không phải là thư mục thực mà là các con trỏ siêu dữ liệu.
Điều này có nghĩa là siêu dữ liệu (metadata) và quyền của thư mục trên Cloud Storage sẽ không hoạt động như trên HDFS. Các ứng dụng Hadoop như Ranger và Sentry có sự phụ thuộc vào các quyền của HDFS. Khi di chuyển các ứng dụng này hãy chú ý các quyền được cấp phù hợp để hoạt động như mong đợi.
4. Cloud Storage không hiển thị tất cả thông tin hệ thống của đối tượng
Nếu bạn chạy lênh như “hadoop fsck -files -blocks” trong thư mục trên HDFS. Bạn sẽ nhìn thấy những thông tin hữu ích như về sức khỏe của các blocks. Cloud Storage trừu tượng hóa toàn bộ lớp quản lý của tất cả lớp lưu trữ. Do đó, khi thực hiện lệnh tương tự như trên, chúng ta sẽ nhận được ” “Filesystem is Cloud Storage.” (By the same token, “no storage management overhead “.
5. Cloud Storage có thể có độ trễ lớn
Cloud Storage có thể có độ trễ cao hơn so với HDFS. Đối với các công việc ETL quy mô lớn thì đây không phải yếu tố quan trọng, nhưng đối với các công việc nhỏ hoặc số lượng file có dung lượng nhỏ nhưng với số lượng lớn hoặc duyệt tuần tự có thể rất nhạy cảm với độ trễ.
II. Ưu điểm
1. Chi phí thấp
Với Cloud Storage, bạn chỉ trả tiền cho những gì bạn sử dụng thay vì mua quá nhiều phần cứng trước và dự đoán cần mua bao nhiêu thiết bị. Các byte bạn mua trên Cloud Storage cũng được sao chép lại, do đó bạn không phải trả tiền cho các phiên bản Google Computer Engine để chạy và sao chép. Theo kết quả của nhóm nghiên cứu Enterprise Strategy Group (ESG) cho thấy các tổ chức chuyển từ HDFS sang Cloud Storage thường có tổng chi phí thấp hơn 57%
2. Tách biệt tính toán và lưu trữ
Khi dữ liệu được lưu trữ trên Cloud Storage thay vì HDFS, bạn có thể truy cập trực tiếp từ nhiều clusters. Điều này giúp xóa hoặc tạo một cluster mới mà không cần di chuyển dữ liệu. Nó cũng được tận dụng các cluster cho các công việc khác.
3. Khả năng tương tác
Lưu trữ dữ liệu trên Cloud Storage cho phép khả năng tương tác liền mạch giữa các phiên bản Spark và Hadoop cũng như các dịch vụ GCP khác. Các tệp Lưu trữ đám mây có thể được nhập vào Google BigQuery và sử dụng Lưu trữ đám mây giúp dễ dàng thử nghiệm và các tác vụ xử lý dữ liệu được quản lý Cloud Dataflow.
4. Tương thích với HDFS vào có hiệu suất tương đương hoặc thậm chí tốt hơn
Bạn có thể truy cập dữ liệu Cloud Storgare từ các Job Hadoop hoặc Spark hiện tại của mình chỉ bằng cách sử dụng tiền tố gs: // thay vì hfds :: //. Trong hầu hết các khối lượng công việc, Cloud Storage thực sự cung cấp hiệu năng tương đương hoặc tốt hơn HDFS trên Persistent Disk.
5. Dữ liệu sẵn sàng cao
Dữ liệu được lưu trữ trong Cloud Storage sẵn sàng cao và được sao chép toàn cầu (khi sử dụng lưu trữ đa vùng – Multi Regional) mà không làm giảm hiệu suất. Cloud Storage không dễ bị tổn thương bởi NameNode hoặc thậm chí là lỗi cụm.
6. Không cần bảo trì
Không giống như HDFS, Cloud Storage không yêu cầu bảo trì thường xuyên như chạy tổng kiểm tra trên các tệp, nâng cấp hoặc quay lại phiên bản trước của hệ thống tệp và các tác vụ quản trị khác. Các nhóm kỹ thuật độ tin cậy trang web (SRE) của Google làm việc này cho bạn.
7. Khởi động nhanh
Trong HDFS, một công việc MapReduce không thể bắt đầu cho đến khi NameNode hết chế độ an toàn. Quá trình này có thể mất từ vài giây đến nhiều phút, tùy thuộc vào kích thước và trạng thái dữ liệu của bạn. Với Cloud Storage, bạn có thể bắt đầu công việc ngay khi các nút tác vụ bắt đầu. Vì Google Cloud tính tiền theo giây, và dễ nhận thấy rằng sự khởi đầu nhanh này dẫn đến tiết kiệm chi phí đáng kể theo thời gian.
8. Bảo mật Google IAM
Sử dụng Cloud Storage thay vì HDFS đưa bạn trực tiếp vào các mô hình bảo mật GCP để bạn có thể tận dụng các điều khiển IAM như Service Account và không cần một hệ thống cấp phép HDFS riêng.
9.Tính nhất quán toàn cầu
Cloud Storage cung cấp tính nhất quán toàn cầu mạnh mẽ cho các hoạt động dưới đây; điều này bao gồm cả dữ liệu và siêu dữ liệu.
- Read-after-write ( Đọc sau khi viết)
- Read-after-metadata-update (Đọc sau khi siêu dữ liệu cập nhật)
- Read-after-delete (Đọc sau khi xóa)
- Bucket listing (Danh sách Bucket)
- Object listing ( Danh sách đối tượng)
- Granting access to resources (Cấp quyền truy cập vào tài nguyên)
Việc nhất quán nghiêm ngặt này làm cho Cloud Storage trở thành một nơi thích hợp cho các điểm đến công việc và tránh được chi phí giải quyết phức tạp không cần thiết cho các đối tượng nhất quán.
Khi bạn lựa chọn HDFS: Bạn có 5 việc cần phải xem xét
1. Các công việc yêu cầu Hadoop 2 nhưng thấp nhất là Hadoop 2.7
Trong các version của Hadoop có khoảng cách rất lớn giữa version 2.0 và 2.7.x. FileOutputCommitter trên Cloud Storage chậm hơn nhiều so với HDFS. Đã có bản vá cho vấn để trên được bắt đầu từ Hadoop version 2.7. Và nó chưa áp dụng cho Cloud Dataproc.
2. Các công việc đòi hỏi hiệu suất low-variance và khả năng xoay vòng trên siêu dữ liệu hoặc dữ liệu đọc nhỏ
Các công việc được dự kiến sẽ chạy ở tốc độ tương tác có thể nhạy cảm hơn với độ trễ của các tác vụ chậm nhất. Các công việc liên quan đến nhiều lần đọc truy cập ngẫu nhiên nhỏ và / hoặc nhiều yêu cầu siêu dữ liệu tuần tự có thể nhạy cảm với độ trễ đuôi cũng như độ trễ lớn hơn của các chuyến đi khứ hồi yêu cầu. Những công việc như vậy có thể phù hợp hơn với HDFS.
3. Các công việc yêu cầu các tính năng giống POISIX
Các công việc yêu cầu các tính năng của hệ thống file như đổi tên thư mục nghiêm ngặt, quyền HDFS chi tiết hoặc liên kết tượng trưng HDFS chỉ có thể hoạt động trên HDFS.
4. Bảng tham chiếu hoặc giá trị tra cứu
Các công việc thường xuyên truy vấn lại cùng một phần dữ liệu và không yêu cầu hoạt động xáo trộn có thể được hưởng lợi từ phiên bản HDFS được bản địa hóa của dữ liệu. Điều đó cho phép các công việc tự động sử dụng bộ đệm. Một thực tiễn tốt nhất phổ biến là duy trì các nguồn bảng tham chiếu trong Cloud Storage nhưng đưa tệp vào HDFS như một bước đầu tiên trong công việc.
5. Phân tích lặp hoặc đệ quy trên các tập dữ liệu nhỏ
Các Job chạy lặp đi lặp lại nhiều lần trên một tập dữ liệu nhỏ, nhỏ hơn nhiều so với tổng bộ nhớ khả dụng, có thể sẽ có hiệu suất HDFS nhanh hơn do bộ đệm bộ đệm. Một lần nữa, một thực tiễn tốt nhất phổ biến là duy trì các nguồn bảng trong Cloud Storage nhưng đưa tệp vào HDFS như một bước đầu tiên trong công việc.
Chuyển đổi từ HDFS sang Cloud Storage
Khi bạn quyết định chuyển đổi việc lưu trữ của mình từ HDFS sang Cloud Storage, bước đầu tiên là cài đặt, cấu hình và bắt đầu thử nghiệm với Cloud Storage.
Nếu bạn đang sử dụng Cloud Dataproc, dịch vụ đám mây được quản lý hoàn toàn của Google để chạy các cụm Apache Spark và Apache Hadoop, trình kết nối Cloud Storage được cài đặt sẵn. Điều tương tự cũng xảy ra với Nền tảng dữ liệu Hortonworks (HDP). Bắt đầu từ HDP 3.0, Cloud Storage đã trở thành một trình kết nối được tích hợp đầy đủ để truy cập dữ liệu và xử lý khối lượng công việc Hadoop và Spark.
Mặc dù MapR không tích hợp với trình kết nối theo mặc định, nhưng chúng cung cấp một hướng dẫn bắt đầu nhanh, dễ thực hiện.
Bạn cũng có thể cài đặt Cloud Storage Connector trên bất kỳ cụm Apache Hadoop / Spark nào bằng cách làm theo các hướng dẫn cài đặt này. Khi bạn đã có được trải nghiệm cơ bản khi sử dụng Cloud Storage Connector, bạn có thể khám phá tài liệu Google Cloud về di chuyển dữ liệu HDFS từ On-Premise sang Google Cloud Platform.
Sau khi cài đặt Cloud Storage Connector, chúng ta sử dụng “gs: //bucket/ foo-data-directory” hoạt động giống như hdfs: //namenode/foo-data- directory.
Chỉ cần thay đổi đường dẫn đầu vào và đầu ra và Cloud Storage sẽ hoạt động cho hầu hết các công việc điển hình mà không cần sửa đổi thêm.
Mẹo và thủ thuật sử dụng trình Cloud Storage Connector
Dưới đây là một số mẹo và thủ thuật cần xem xét khi bạn chọn công việc nào sẽ di chuyển với Cloud Storage Connector.
1. Tăng fs.gs.block.size cho các file có kích thước lớn
Vì Cloud Storage trừu tượng hóa các kích thước khối bên trong, nên giá trị mặc định là 64 MB. Nếu bạn có tệp lớn hơn ~ 512MB và công việc lớn, bạn có thể xem xét tăng giá trị này lên 1GB. Vì đây là giá trị giả mạo chỉ dành cho các cuộc gọi Hadoop gọi là “getSplits“, nó có thể khác nhau cho mỗi công việc hoặc thậm chí trên cùng một bộ dữ liệu cơ bản.
Bạn muốn nhắm tới ít hơn 10.000 đến 20.000 lần phân tách đầu vào. Trong hầu hết các tình huống, điều này chuyển thành 10TB dữ liệu là điểm bùng phát khi bạn muốn đặt fs.bs.block.size thành 1GB.
Một cách khác để suy nghĩ về cài đặt này là thử và thực hiện mỗi tác vụ bản đồ mất khoảng 60 giây để chạy cho mỗi lần phân tách đầu vào. Bằng cách đó, việc thiết lập và lập lịch trình JVM của nhiệm vụ là tối thiểu so với thời gian chạy tác vụ.
2. Tận dụng các lớp lưu trữ cho Hadoop.
Google Cloud Storage cung cấp bốn lớp lưu trữ, tất cả đều có cùng thông lượng, độ trễ thấp và độ bền cao. Các lớp chỉ khác nhau bởi tính khả dụng, thời lượng lưu trữ tối thiểu và giá cả cho việc lưu trữ và truy cập. Các công cụ và API lưu trữ đám mây để truy cập dữ liệu vẫn giống nhau bất kể lớp lưu trữ. Bạn có thể viết một công việc Spark hoặc Hadoop dựa trên dữ liệu được chỉ định có chi phí thấp hơn mà không cần dịch vụ lưu trữ riêng.
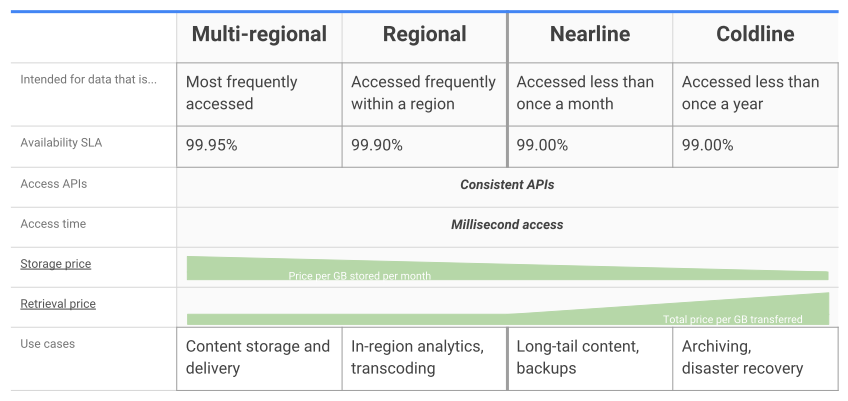
Lưu ý về Regional Storage: hầu hết khối lượng công việc Hadoop sẽ sử dụng Regional Storage hơn là Multi Regional để đảm bảo xử lý xảy ra trong cùng khu vực với dữ liệu .
Với những chia sẻ bên trên, hy vọng cung cấp cho các bạn cái nhìn bên dưới của Hadoop HDFS và Cloud Storage và quyết định lựa chọn phương pháp nào là tối ưu cho bạn. Các bạn hãy liên hệ với các chuyên gia – Cloud Ace Việt Nam – để được hỗ trợ tốt hơn.