Trước khi vào thực hiện thì mình cần tìm hiểu một số khái niệm liên quan.
Hadoop là gì?
Hadoop hay còn gọi là Apache Hadoop là một software framework hỗ trợ các ứng dụng phân tán dữ liệu chuyên sâu theo một giấy phép miễn phí. Nó cho phép các ứng dụng làm việc với hàng ngàn máy tính tính toán độc lập và petabyte dữ liệu. Hadoop được bắt nguồn từ các bài báo MapReduce của Google và Google File System (theo wikiperdia).
Hadoop làm việc trên các file system gọi là HDFS. Nó có 2 tác vụ chính là Map và Reduce.
- Map: chạy song song với một tập dữ liệu lớn để tạo ra kết quả trung gian.
- Reduce: build kết quả cuối cùng dựa trên kết quả chạy của Map.
PySpark là gì?
Py ở đây là Python và Spark là Spark là một framework được xây dựng để hỗ trợ việc xử lý dữ liệu một cách phân tán được phát triển bằng ngôn ngữ Scala. Lợi thế là nhanh, tiếp cận dễ dàng, hỗ trợ nhiều kiểu tính toán hơn Hadoop MapReduce.
PySpark là một công cụ để giúp các lập trình viên python có cơ hội tiếp cận với Spark.
Dataproc là gì?
Dataproc là dịch vụ của Google Cloud Platform (GCP) để quản lý và chạy các ứng dụng Hadoop hoặc Spark (link tham khảo thêm). Dataproc xử lý theo từng Job được khai báo .
Dataproc hiện hỗ trợ một số loại Job Type và ngôn ngữ sau:
- Hadoop/ Spark: Java (link tham khảo)
- PySpark: python
- SparkR: R
- SparkSQL/Hive/Pig/: script text
Khi nào dùng JobType nào? hay nói cách khác là mình sẽ dùng script hay java hay python hay R? Câu trả lời đơn giản là bạn master được ngôn ngữ nào thì dùng ngôn ngữ đó. Nhưng dữ liệu được chia thành dữ liệu có cấu trúc, dữ liệu bán cấu trúc và dữ liệu không có cấu trúc. Thông thường, đối với dữ liệu có cấu trúc , các bạn sử dụng script là dễ xử lý hơn, còn dữ liệu bán cấu trúc hoặc không có cấu trúc thì dùng java/python/R là dễ xử lý hơn.
Vậy chạy Hadoop/ PySpark trên Dataproc như thế nào?
Trong bài này, mình sẽ demo cho mọi người chạy một ứng dụng PySpark đơn giản – wordcount trên Dataproc. (ứng dụng trên hadoop và Dataproc thì các bạn có thể tìm hiểu thêm ở đây ).
Để tạo Job (hay còn gọi là Submit Job) thì bạn cần phải tạo cluster, config firewall,..các bước đó giống như ở đây,. Bài viết đó tạo tên VM Instancecó tên là cluster-demo nó tương đương với tên VM Instance bài viết này là dataproc-cluster với dataproc-cluster-m là cluster chính . Mình sẽ làm việc chủ yếu trên dataproc-cluster-m. Toàn bộ các dòng lệnh mình thực hiện trên Master Node nhé
Chuẩn bị dữ liệu:
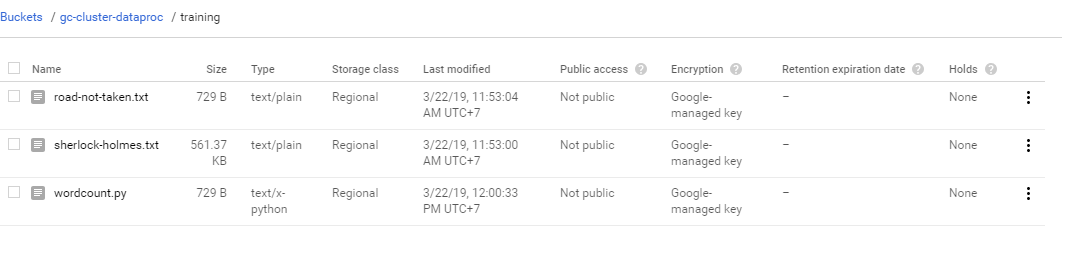
Dataproc có thể truy cập và file://, hdfs:// và gs://. Cho đơn giản thì mình sẽ tạo gs (cloud storage) để lưu trữ các file text và file source của mình. Ở đây mình tạo mới Bucket là gc-cluster-dataproc
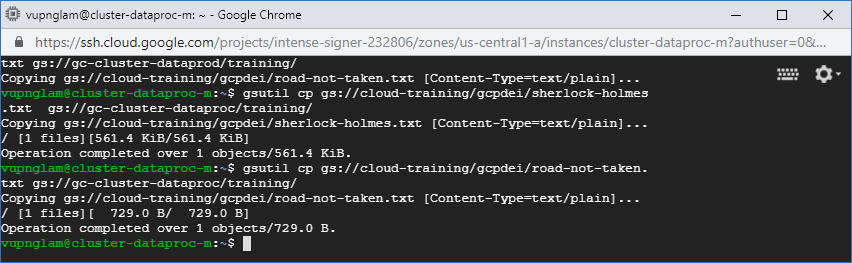
Ở đây mình sử dụng 2 file text road-not-taken.txt có chứa 24 dòng và sherlock-holmes.txt chứa 12651 dòng. mình sẽ download nó về . Ở đây mình sẽ copy dữ liệu từ cloud-training/gcpdei về bucket gc-cluster-dataproc của mình.
gsutil cp gs://cloud-training/gcpdei/road-not-taken.txt gs://gc-cluster-dataproc/training/
gsutil cp gs://cloud-training/gcpdei/sherlock-holmes.txt gs://gc-cluster-dataproc/training/
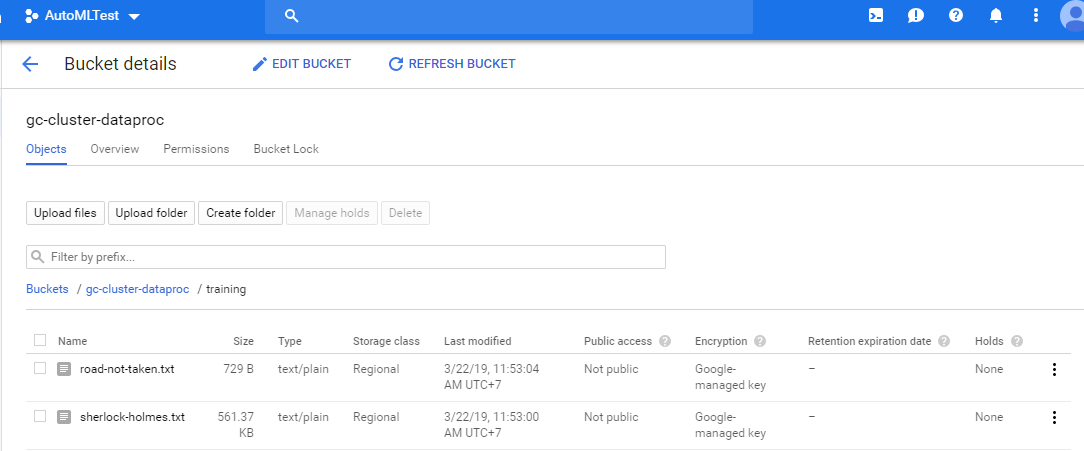
Xem nội dung của cac file vừa copy về bằng cách click vào file muốn xem trên bucket của mình
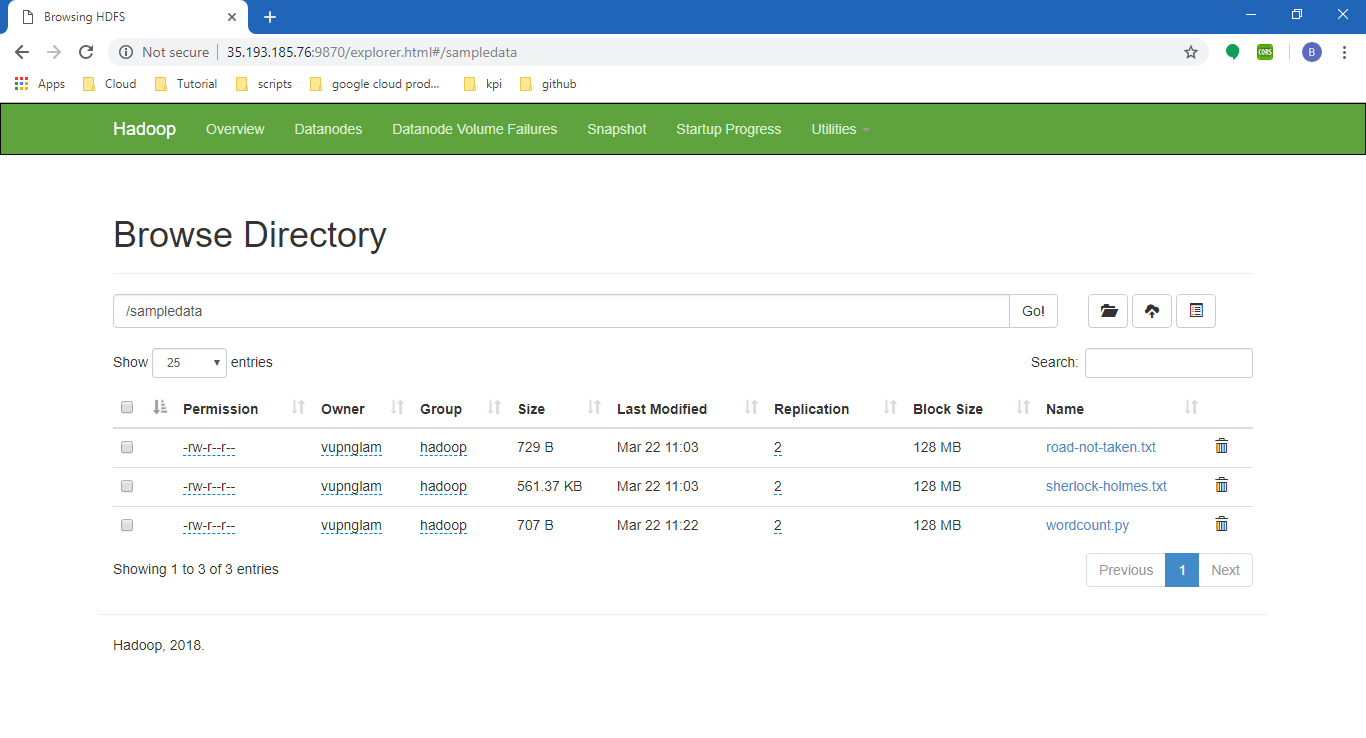
Kiểm tra hadoop
hadoop fs -ls /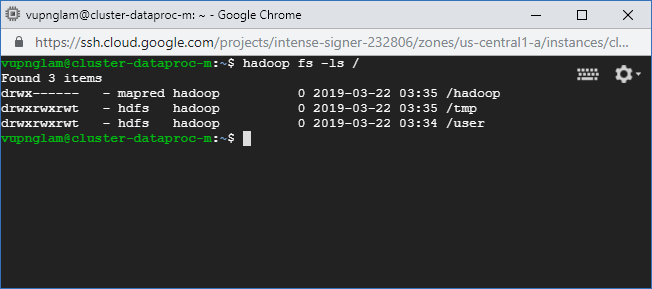
Trong SSH Terminal của Master Node. Bạn sử dụng nano để tạo file mới tên là wordcout.py với nội dung như sau:
from pyspark.sql import SparkSession
from operator import add
import re
print("Okay Google.")
spark = SparkSession
.builder
.appName("CountUniqueWords")
.getOrCreate()
lines = spark.read.text("gs://gc-cluster-dataproc/
training/road-not-taken.txt").rdd.map(lambda x: x[0])
counts = lines.flatMap(lambda x: x.split(' '))
.filter(lambda x: re.sub('[^a-zA-Z]+', '', x))
.filter(lambda x: len(x)>1 )
.map(lambda x: x.upper())
.map(lambda x: (x, 1))
.reduceByKey(add)
.sortByKey()
output = counts.collect()
for (word, count) in output:
print("%s = %i" % (word, count))
spark.stop()
Chú ý đoạn code này :
lines = spark.read.text("gs://gc-cluster-dataproc/training/road-not-taken.txt")
// nếu bạn đặt bucket tên khác thì thay thế gc-cluster-dataproc bằng tên bucket mà bạn đặt nhé.Sau khi tạo xong file wordcount.py. thì mình cũng copy nó vào bucket luôn.
gsutils cp wordcount.py gs://gc-cluster-dataproc/training/Sau khi thực hiện xong, thì trên bucket của mình sẽ có tổng cộng là 3 file
Tạo Job (Submit Job)
Vào DataProcc/ Job và Click Submit Job để tạo Job với các tham số co bản sau
| Property | Value (type value or select option as specified) |
| Region | <your-region> |
| Cluster | dataproc-cluster |
| Job type | PySpark |
| Main Python file | gs://gc-cluster-dataproc/training/wordcount.py |
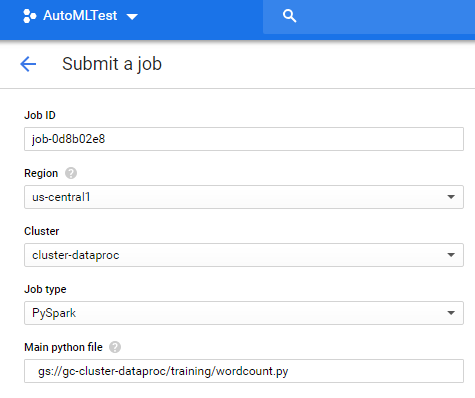
Chú ý : Main python file: đây chính là đường dẫn đến file wordcout.py của mình trên Bucket
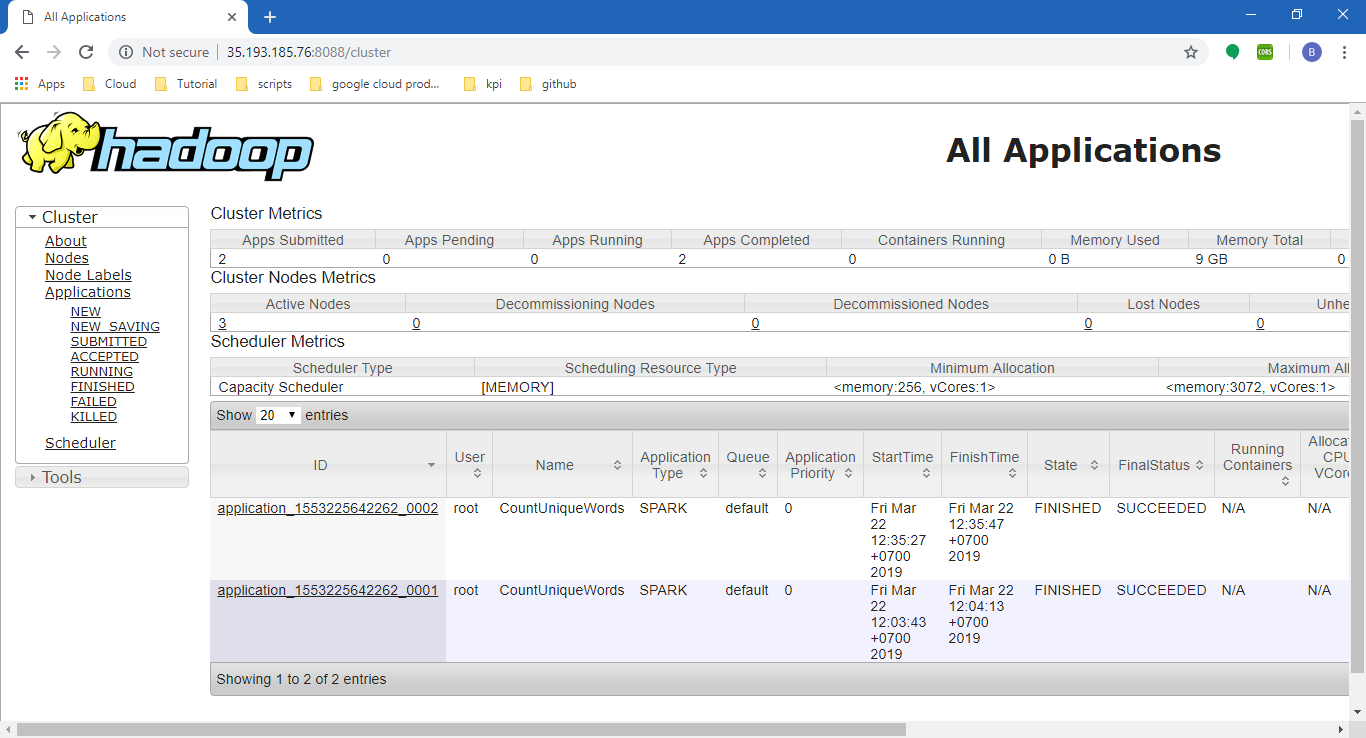
Sau khi Submit. đợi 1 chút thì sẽ được kết quả như sau:

Thử click vào job để xem chi tiết xem nào.
Vậy là đã thành công rồi đó, các bạn có thể vọc thêm nếu các bạn thích. Bạn có thể xem một số giao diện liên quan như hadoop <External IP>: 8088, hadoop admin <External IP>: 9870. (Để biết External IP. bạn hãy vào VM Instance , External IP của cluster-dataproc-m nhé)
Liên hệ ngay với chúng tôi, Cloud Ace Việt Nam để được tư vấn về G Suite, GCP.